I’ve written a book on programming aimed at beginners. It’s free (licensed under a Creative Commons license) and available here:
Feel free to check it out and let me know if you have any feedback.
I’ve written a book on programming aimed at beginners. It’s free (licensed under a Creative Commons license) and available here:
Feel free to check it out and let me know if you have any feedback.
Since I spent some time tweaking the AI in Freekick 3, I thought I should write down some of the implementation details for future reference.
The AI has quite a simple general structure. Apart from the special cases like restarts, goalkeeper AI etc. the main gameplay AI consists of three states: defensive AI, offensive AI and the AI when the agent is about to kick the ball. Whether a player is in the defensive or offensive state depends on the match situation (where the ball is, who has the ball) and the team tactics (agent’s position).
The defensive state is basically a decision “where should I stand to make the opponent’s offensive difficult”. There are a few options: try to take the ball from the opponent, try to block an opponent’s pass or shot or guard some area or opponent. The AI simply assigns scores to each action and picks the action with the highest score. (This, I suppose pretty standard AI technique, seems to be inspired by utility functions and is used throughout the Freekick 3 AI.)
The offensive state is even simpler than the defensive state: either the player tries to fetch the ball or tries to place himself in the best possible supporting position, which should be somewhere that can be passed to, far away from opposing players, and a good shot position. (The AI builds a kind of an influence map that is also affected by some soccer-specific things such as the offside rule.)
Probably the most important decision the AI has to make is what to do when the agent has the ball. Again, like with the defensive state, the AI has a few different possible actions, and it assigns scores to all of them and simply picks the action with the highest score.
The possible actions are Pass, Shoot, Long Pass, Clear, Tackle and Dribble. I’ll start with the Pass action.
When deciding the pass target, the AI loops through all of the friendly players and keeps track of the best option. For each player that’s not too far or too close, the AI considers either passing directly to the player or trying a through-pass. The base score for the pass is highest for players nearer the enemy goal, and then decreased for each opponent player that is seen as a possible interceptor.
The Shoot action score is basically a function of distance to the opponent’s goal and the distance from the opponent’s players (especially the goal keeper) to the possible shot trajectory.
The Long Pass action is actually a composite of Shoot and Pass – it checks for the Shoot and Pass action scores of the friendly players and chooses to make a long pass (or cross) to the player with the highest score. As with other actions, the score is multiplied by a team tactics coefficient, allowing the coach to influence the team’s playing style.
Clear and Tackle are basically emergency brakes that the AI can pull in a situation where the ball needs to be kicked away from the own goal or the opposing players.
With Dribble, the AI creates a few possible rays at regular angle intervals around the agent as possible dribble vectors and assigns scores to each of them. Similar to shooting, the score is higher near the opponent goal, but decreased by opponent presence.
So, in the end, the AI is composed by several rather simple techniques. It’s all heuristics without any algorithms providing optimal solutions (if any can even be used in soccer AI). It uses some simple seeking behaviors (arrive at a position, chase the ball). There’s one simple state machine, with state transitions decided mostly by the ball position. The top level AI is built around simple if-then-else-statements (I suppose you could call them decision trees). Lots of the decision making uses some sort of fuzzy logic, even though it’s not really structured like that (instead the code itself is fuzzy). Still, the AI manages to seem smart in most cases, it plays rather well and presents a challenge for the human player (for me, at least).
There are still quite a few standard AI techniques that I haven’t implemented which might make sense for Freekick 3. For example it might be interesting to experiment with adding some kind of learning ability to the AI, which should be possible using reinforcement learning, or adding a more complicated planning process with the use of a decision network. A useful first step would be to extract all the used generic concepts like decision trees and fuzzy logic to their own code pieces, which would enable experimenting with things like learning a decision tree.
My conclusion is that there are lots of different game AI techniques, many of which are quite simple, and the key to creating a fun AI is to find out which techniques to use for which problem and how to combine the techniques. The techniques are often intuitive but can be also described mathematically, so that when reading up on game AI, you may, depending on the material, get an impression that game AI is either very non-scientific or very mathematical (and therefore difficult), while I think it can be either, depending on how you look at it.
For the interested, the ~500 lines of Freekick 3 AI that make up the core can be found at GitHub.
It’s been a while since the last post.
This post is to announce a new version of Freekick 3, the latest rewrite of my project of writing a soccer game. It doesn’t have fancy graphics (on the contrary, it’s very ugly), but it tries to provide a fun soccer game to play nevertheless.
This is actually the first announcement of Freekick 3. The previous announcement on the Freekick series was the announcement of Freekick 2. Here’s a short overview of the features.
– A few different game modes, including friendly games, knockouts, leagues, seasons and a mockup of a career mode.
– The team, league and player data is not included, but can be imported to Freekick 3 either from Sensible World of Soccer data files or, my favourite, from Wikipedia. By having a script to fetch all the data from Wikipedia it’s ensured that the data is relatively up-to-date and that there’s a fair amount of teams to play against.
– The AI is improved and may provide a nice challenge.
– You can either control the whole team in the match or choose to just control one player.
You can download Freekick 3 (source) from https://github.com/anttisalonen/freekick3. I’ll show a quick tour around Freekick 3.

This is the main menu (quite similar to Freekick 2).
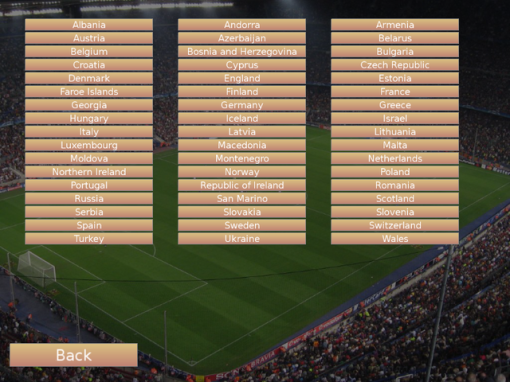
After fetching the data from Wikipedia you have lots of teams to choose from.

You can tune the line up before the match.
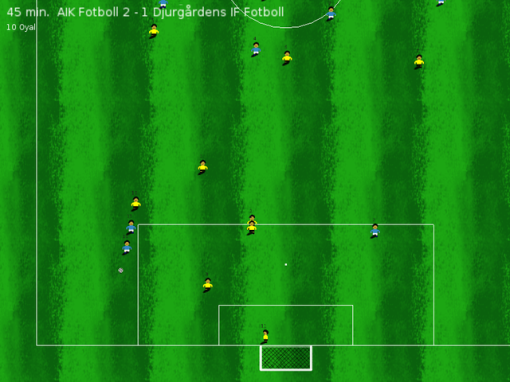
During a match – about to cross.
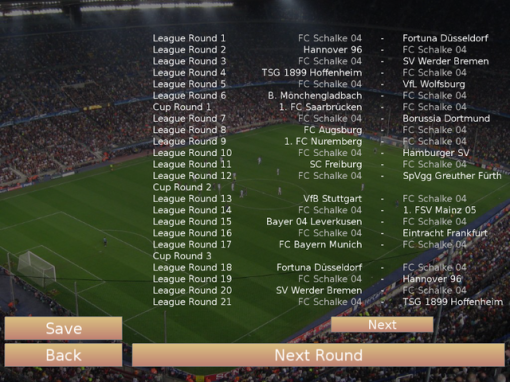
Career mode includes a league season along with the national cup.
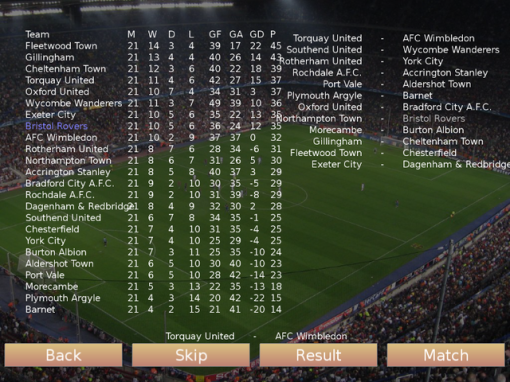
Football league two mid-season table.
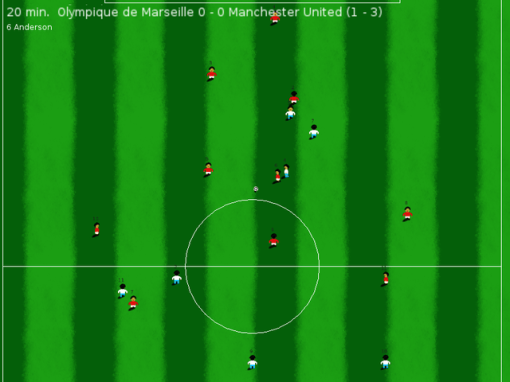
Fighting for the ball mid-field.
Those of you who’ve been checking out my projects might have noticed that I wrote my latest one in C++. The two previous projects I had written in Haskell. So why the switch? I’ll write down a small summary of the pros and cons of the both languages that influenced my decision.
I’ll start with the things that spoke for Haskell.
And now for the cons, or, put in a more positive light, pros for C++.
As can be seen from the list, the negative issues I see concerning Haskell are mostly not about the language itself but the infrastructure. That makes sense, I guess; Haskell, although it has a great community, is a less used language, especially in the industry, which makes it more difficult to establish an infrastructure that can compete with the one of, say, C++. The problems I have with C++, on the other hand, concern the language itself, which, although useful, is not really what one might consider the crown jewel of language design.
The infrastructure is at least something that can be fixed.
Behold, Kingdoms 0.1.0 has been released. Kingdoms is a hobby project of mine I’ve been working on for the past couple of months. It’s a strategy game, where you lead a nation from stone age until the bittersweet end – in other words, a Civilization-like game. I’ve been wanting to write one for a long time, and I’m glad to see it’s doable.
It borrows features from all Civilization games I’ve played: graphics from Civ 1 (because I’m no artist), the configuration file type from Civ 2 (back when it was simple), strategic resources and culture from Civ 3 and (part of) the combat system from Civ 4. By the way, that’s also the reason why I wanted something else than FreeCiv: I find it’s too similar to Civ 2, which was never my favorite Civ game.
Here are some screenshots:

Babylonians vs. Aztecs

A map editor is included
You can get Kingdoms from its web page – there’s the source as well as the Windows binary. There are still quite a few features I wanted to implement but haven’t had the time yet, so if something bugs you, let me know.
I noticed I still haven’t blogged about a project I worked on some time ago, so here goes.
A long time ago I wrote a small library for wrapping OGRE in Haskell. I wrote it manually, i.e. first writing some C functions that call C++ and have a C interface, and then wrote some Haskell functions to call the C functions. That’s the principle when wrapping C++ libraries in most higher level languages, mainly because most language implementations support calling C, but not C++.
Now, by writing the whole wrapper manually you have the complete power of the resulting interface, so you can try to bend the C interface so that the resulting interface has the natural feel of the higher level language you’re writing the binding for. The negative side to this is, of course, that it’s lots of work, and more or less tedious at that. There are therefore a lot of programs that automate some or part of the process of writing bindings to C libraries. So when wrapping a C library for Haskell, you can use a tool like hsc2hs, bindings-DSL or c2hs.
But it gets more problematic when you want to wrap C++ code. In the end you somehow have to wrap the C++ code to C – either manually or automatically. Some C++ libraries maintain their own C wrappers, like bullet and LLVM. For others, the wrapper writers must either write or generate their own C wrappers. When it comes to Haskell bindings for C++ libraries, the C wrappers were written manually at least for Irrlicht. I also wrote the C wrapper manually for the first versions of Hogre. As for the libraries that generate the C wrapper using a tool, there’s at least qtHaskell.
Now, at some point it got tiresome to manually write the Haskell bindings to Hogre, so I wrote a tool to automate it. Actually, there are two tools: cgen is a program that parses C++ header files and creates a C wrapper around the C++ library, and cgen-hs is a tool that parses the generated C header files and creates a Haskell wrapper around the C library. Using these two tools I created the newest version of Hogre, which is a lot more complete than the previous, manually written binding.
I also wrote a small example on how cgen works that I’ll demonstrate here. The input is Animals, a C++ library that allows access to a programmatic use of a wide range of animals. It’s a header-only library because I wanted to keep it simple, but that doesn’t really make a difference here. It’s split across three header files, listed here:
namespace Animals {
class Animal {
public:
Animal() : age(0) { }
~Animal() { }
virtual void make_sound() = 0;
int get_age() const
{
return age;
}
void increment_age()
{
age++;
}
private:
int age;
};
class Dog : public Animal {
public:
Dog() { }
void make_sound()
{
std::cout << "Growl!\n";
}
};
class Sheep : public Animal {
public:
Sheep(int wooliness_level_ = 0)
: wooliness_level(wooliness_level_)
{ }
void make_sound()
{
std::cout << "Baa!\n";
}
void shear()
{ /* something */ }
private:
int wooliness_level;
};
}
So, given this piece of code one can feed it to cgen, which generates a C interface for it. The result looks something like this (simplified):
/* Sheep.h */
void Animals_Sheep_delete(Sheep* this_ptr);
Sheep* Animals_Sheep_new(int wooliness_level_);
void Animals_Sheep_make_sound(Sheep* this_ptr);
void Animals_Sheep_shear(Sheep* this_ptr);
/* Sheep.cpp */
void Animals_Sheep_delete(Sheep* this_ptr)
{
delete this_ptr;
}
Sheep* Animals_Sheep_new(int wooliness_level_)
{
return new Sheep(wooliness_level_);
}
void Animals_Sheep_make_sound(Sheep* this_ptr)
{
this_ptr->make_sound();
}
void Animals_Sheep_shear(Sheep* this_ptr)
{
this_ptr->shear();
}
So there we have a C wrapper for a C++ library ready for compilation.
For writing the Haskell binding, the next step is to run the next tool, cgen-hs. It takes the generated headers of the C wrapper as input, and as output creates a Haskell library that wraps the C library. The output looks something like this:
{-# LANGUAGE ForeignFunctionInterface #-}
module Sheep(
sheep_with,
sheep_delete,
sheep_new,
sheep_make_sound,
sheep_shear
)
where
import Types
import Control.Monad
import Foreign
import Foreign.C.String
import Foreign.C.Types
sheep_with :: Int -> (Sheep -> IO a) -> IO a
sheep_with p1 f = do
obj <- sheep_new p1
res <- f obj
sheep_delete obj
return res
foreign import ccall "Sheep.h Animals_Sheep_delete" c_sheep_delete :: Sheep -> IO ()
sheep_delete :: Sheep -> IO ()
sheep_delete p1 = c_sheep_delete p1
foreign import ccall "Sheep.h Animals_Sheep_new" c_sheep_new :: CInt -> IO Sheep
sheep_new :: Int -> IO Sheep
sheep_new p1 = c_sheep_new (fromIntegral p1)
foreign import ccall "Sheep.h Animals_Sheep_make_sound" c_sheep_make_sound :: Sheep -> IO ()
sheep_make_sound :: Sheep -> IO ()
sheep_make_sound p1 = c_sheep_make_sound p1
foreign import ccall "Sheep.h Animals_Sheep_shear" c_sheep_shear :: Sheep -> IO ()
sheep_shear :: Sheep -> IO ()
sheep_shear p1 = c_sheep_shear p1
Then one can write a Haskell program using this new Haskell library, and run it for the output:
$ cat Main.hs
module Main
where
import Control.Monad (replicateM_)
import Types
import Animal
import Dog
import Sheep
main = do
dog_with $ \d ->
sheep_with 1 $ \s -> do
dog_make_sound d
sheep_make_sound s
sheep_shear s
replicateM_ 5 $ animal_increment_age (toAnimal s)
animal_get_age (toAnimal s) >>= \a -> putStrLn $ "The sheep is now " ++ show a ++ " years old!"
$ ./Main
Growl!
Baa!
The sheep is now 5 years old!
So, everything seems to work well, and the newest Hogre version can be found at Hackage, as well as cgen.
Cgen is, however, in a very early stage of development and has, therefore, some weaknesses. First of all, it’s not a complete C++ parser, not even close, so it fails to parse many C++ header files. After configuring it for OGRE, it does manage to parse about two thirds of the OGRE headers, which is a good start, I guess. The C++ parser was the first real parser I wrote using Parsec, so a rewrite is probably the way to go.
Second of all, as I’ve only seriously used cgen for OGRE, it makes some assumptions about the C++ headers that may not hold for other libraries. The most critical one is probably that cgen-hs expects that all the classes and functions to wrap are in some namespace, which leads to problems when wrapping libraries that reside in the global namespace.
The third weakness is that it the generated Haskell functions are simply all in the IO monad, which suits well for OGRE (which doesn’t really have that many pure functions), but may be far from ideal for another library. Finally, cgen currently doesn’t support any class templates, neither wrapping them or using them as parameters or return values, so wrapping interfaces that rely heavily e.g. on STL will be troublesome. For Hogre this is not really a killer, although it does prevent the Hogre user from using some features that are available in OGRE.
All in all, however, cgen is working well for Hogre, and if you’re planning on writing a binding for a C++ library, you can give it a try. For more information, see the cgen homepage, a simple example, and the Hogre homepage.
About a month ago I announced my then-latest programming project, Star Rover 2. It’s a space flying game written in Haskell, and while programming that was fun and I learnt a lot from the project, it was time to find something else to do. So I started another soccer project, again in Haskell (like in September 2008), but with a bit more Haskell experience under my belt.
And now, after almost a month, it’s time for the first release. The new soccer game is called freekick2, and it’s an open source 2D arcade style soccer game.

If you have cabal, you can install it with a simple cabal update && cabal install freekick2. Here’s a screen shot from a menu:

The freekick2 distribution includes only a few fantasy teams, but you can use the data files from a Sensible Soccer game for some additional realism.
One lesson I learnt when doing Star Rover 2 is that I should avoid over-engineering like plague, as that was probably one reason why I couldn’t get the first Freekick versions in a releaseable state.
Freekick2 now consists of about 3200 lines of Haskell code, around 1000 more than Star Rover 2, and it’s also a bit fancier, graphics-wise. With Star Rover 2 I used monad transformers to handle the main loop and state changes, which worked pretty well, and I’m using the same technique with freekick2. I still haven’t figured out the whole FRP thing, but game programming in Haskell seems to work out pretty well without.
Things I’ve learnt while programming freekick2:
* Texture mapping with OpenGL in Haskell. To load the textures you need to play around with pointers a bit, which are not really that usual in Haskell. But you can do it, and with the help of some great small libraries like pngload it’s relatively simple in the end. Adding dynamic recoloring of the textures after loading them (to support multiple kit colors) was fun as well.
* Parsing binary data in Haskell. Over a year ago, when I was writing Freekick in C++, I wanted to deserialize the SWOS data files (the format’s known; many thanks to the ones who figured the format out) and I thought parsing binary data sounds like a job for C or C++. The result from back then is about 850 lines long and took a few hours to write. Granted, it also generates some XML. Now I wrote a program to do the same task in Haskell; the result has 250 lines and was written in less than two hours. The Haskell version also includes code for writing SWOS data files – a feature I added just because it was so easy to do. Later, for the freekick-internal data structures, I let BinaryDerive derive the serialization/deserialization code for me. Needless to say, I won’t be doing binary data parsing in C anymore if I get to choose.
* Template Haskell. The state in freekick2 changes pretty often, and is managed in a State monad. I needed a lot of functions of type (FieldType -> FieldType) -> State -> State (like already with Star Rover 2), usually one for each field in a record, and so I let TH generate them all for me. Bulat’s tutorials (links to them can be found here) were a life saver.
* Implementing a GUI with colors, textures and dynamic content, with a tree-like hierarchy for screens.
* Use of the existential quantification language extension for heterogeneous collections. I’ve spent some time with object oriented design in the past, which sometimes leads to object-oriented designs in Haskell, so that something like existential types are needed. In this concrete case, I created the class Sprite, with both the player and the ball implementing it. The easiest way to draw all sprites sorted by depth is then to just put all sprites in one list and sort it. Without existential quantification, I would’ve had to write code to sort the players and then call the draw method of the ball somewhere between the draw methods of the players.
So, programming in Haskell is more fun than ever, and the productivity boost given by Haskell is starting to show more and more.
Here’s the announcement of my latest programming project. It’s called Star Rover 2, and it’s a space flying game. You can fly around in space, trade goods, fight against other ships and complete missions for different governments. It features different difficulty levels, a high score list and several ways for the player to play the game. It’s also the first game I wrote in Haskell that’s actually playable.

The game itself is quite simple: you start on a planet, and you can buy some cargo if you want before launching into the space. In space, you can fly to other planets and see if you can sell your cargo for a better price. There are other ships in space as well, and you’ll get interrupted every once in a while when coming across one, with the possibility of attacking the other ship. If you win, you get their cargo, and the various governments may have their opinions about the attack as well.

Combat in Star Rover 2
As the game progresses, you may earn a reputation among the governing bodies, which leads to new dangers and possibilities. The international relationships are complicated, and attacking a ship of one nationality may not only affect the nationality being attacked but their friends and enemies as well. By playing your cards right you can receive missions from governors, and by completing them you may boost your ranking further.

Captured cargo
The game is quite non-linear; it ends when your ship is destroyed often enough and you are too weak to continue, or when you choose to retire. At the end, your achievements are rated and you may make it to the high score list. Until then, you may choose your activities freely.
You can find Star Rover 2 at Hackage, so if you have cabal, you can install it by running cabal update && cabal install starrover2. You can also fetch the sources from github. As for dependencies, you’ll need SDL, OpenGL and FTGL.
In the beginning, Star Rover 2 was more or less a test of whether I can actually concentrate on one project enough to have a playable game in the end, and I’m glad it’s now reached a state where it can be released. Other than that, I was curious to see what programming such a game actually is like in Haskell, and I’m quite pleased with the results. I started working on Star Rover 2 on my spare time pretty much exactly a month ago, and now it amounts to about 2000 lines of Haskell code. I was a bit worried I couldn’t write a larger project in Haskell, but now I can see how well Haskell scales up to complex tasks. This was also my first project where monad transformers actually came in very handy.
Any feedback and bug reports are of course very welcome.
If you’re planning on writing 3D software in Haskell, here are some tips.
A few months ago I was planning on programming a 3D game in Haskell and was browsing the options for a 3D library. In general, there are a couple of low-level APIs (OpenGL and Direct3D) and a few higher-level libraries built on top of those low-level APIs (OGRE, Irrlicht, and more). Using a low-level API has the known advantages (fine-grained control) and disadvantages (lots of code to write).
It turned out that limiting the programming language to Haskell is quite restrictive; almost all higher-level libraries are intended for using with C++ (Panda3D being an exception with Python as the intended language; the library itself is written in C++, though). So what you need is Haskell bindings for the libraries. There’s a Haskell binding for OpenGL, which is used for (apparently) all 3D games written in Haskell. A few months ago it was the only option and, if you’re doing anything more complicated than rendering a few models in a scene, it still is.
The problem is that binding a C++ library is rather complicated and basically boils down to either writing C code to wrap the C++ interface and then interfacing the C code in Haskell using FFI or automatically generating the C interface (as well as the Haskell FFI code that wraps it). The latter option was chosen for at least the GUI widget libraries wxHaskell and qtHaskell.
However, a few Haskell bindings for 3D libraries have appeared. There’s a very primitive binding to OGRE written by the author of this post (with examples) as well as at least a start of a binding to Irrlicht by Peter Althainz. So there appears to be a bit of activity regarding the use of higher-level 3D libraries in Haskell, which is good news, I guess.
One more note regarding the Haskell bindings for Ogre: you can do some simple things like adding models and a camera, and moving them around, but that’s about it, since I haven’t really had the motivation or need to provide support for anything else. The bindings are relatively simple to extend, though, so if you use the bindings and miss a feature, go ahead and let me know.
In this blog post, I list some gem-like web pages that are worth reading if you want to become a better software developer. They’re not simply some sites where you can read about the hype of the week, instead they include insightful material that actually makes you see software development from a whole different perspective.
The need for mentioning the following sites arises from the fact that most web sites and blogs I find in the net usually make me think the writer either tells me some basics about programming I learned years ago or tries to convince me to use some new, brilliant technology which usually involves XML and/or Java. I often get the feeling I’m not part of the target audience and look for things that do a better job on motivating me. As it is quite difficult to find such sites, I’ll spend the few minutes to list some of the sites I’ve found interesting.
Some time ago I stumbled upon a web site called Joel on Software. It’s basically a blog by an experienced software developer, with interesting stories about our industry for us all to read about. It was actually the first software related web page I had found in a long time that managed to inspire me. My favorite article is “Can your programming language do this?“. As another example, if you’ve ever wondered about the Hungarian notation – or cursed at the coding guidelines that force you to use it, even if you can’t see the usefulness behind it, go read what Joel has to say about its history and things may become more clear, although not necessarily less frustrating.
I was glad to find such a page and was hoping to find more. Later I stumbled upon the page of Paul Graham. He shares some similarities with Joel – they both have founded a start-up company and written a lot of nice texts about software development. As a programming language enthusiast, I especially find the essays by Paul Graham involving Lisp interesting.
Some days ago I was looking for a new book on software development to buy and came across Clean Code by Robert Martin. I haven’t bought the book – yet – but searched for some related material and stumbled upon a presentation by Robert Martin titled “What Killed Smalltalk Could Kill Ruby, Too” as well as a blog post drawing parallels between the aforementioned languages and functional languages, namely Lisp and Haskell. The presentation seems very insightful and makes me not only want to learn more about the history of programming languages but also get a copy of the book.
Gaining interest on the new, modern software development techniques I read about TDD and BDD. And when you read about acronyms as these you can’t help coming across the webpage of Martin Fowler sooner or later. Here I also found an interesting text about DSLs, which I feel is an increasingly important – and interesting – topic.
Sites like these help me learn about the new developments in our industry and also make me a better, more efficient developer while still preserving the fun factor. Keep it up!
